Data Leakage Definition
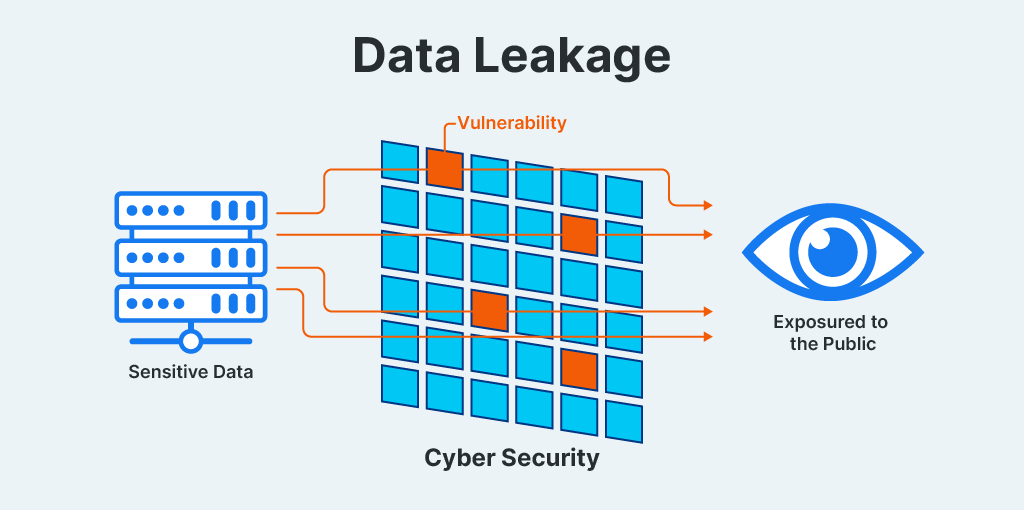
Data leakage is a subtype of data loss. Data leakage occurs when sensitive data is exposed to the public, typically due to errors in configuration. Negligence, malicious intent, and human error can all play a role in data leaking, but a close focus on secure configuration can help prevent it.
Data leakage also occurs when features or data points that should not be available are inadvertently included in a machine learning training dataset, causing the wrong data to be incorporated into model training. Later, the model performs poorly on new, unseen data.
Preventing data leakage is crucial for preventing data loss, providing reliable security, and ensuring that machine learning algorithms are accurate.
Data Leakage FAQs
What is Data Leakage?
Data leakage in cyber security refers to a specific kind of sensitive data loss—one that happens due to misconfigured security settings, weak access controls, and software vulnerabilities. Publicly accessible databases that contain sensitive information, unsecured cloud storage, or improperly protected network shares are all examples of sources of this kind of vulnerability.
This kind of data loss can expose customer details, intellectual property, trade secrets, or other valuable information and hurt the integrity and availability of the system.
Implement and maintain the system according to secure configuration guidelines, and use a few key tools that help mitigate the risks that lead to data leakage. Also involve security in the review of design and new feature roll-outs, especially external portal use cases:
- Access controls
- Encryption
- Data loss prevention (DLP) solutions
- Data exposure prevention (DEP) solutions)
- Conduct regular security assessments
- Up-to-date software patches
What is Data Leakage in Machine Learning?
Data leakage in machine learning occurs when training data is inadvertently and inappropriately exposed to other data that skews the model. This is a common problem for complex datasets in particular that affects the ability of prediction models to perform and generalize. For example:
- Time series datasets which make creating training and test sets especially challenging;
- Graph problems for which random sampling methods can be difficult to construct;
- Analog observations such as images and sounds with samples stored in separately sized files with timestamps.
Data leakage in machine learning is different from data breach, data loss, data exfiltration, and data exposure in a few key ways:
- Data source. External data sources with information about or highly correlated with the target variable can mistrain the model if they are exposed to it. To prevent data leakage, carefully separate training, validation, and test datasets.
- Future data. Information that would not be available at the time of prediction is mistakenly included in training data.
- Data preprocessing. Preprocessing steps such as scaling or imputation may inadvertently introduce information about the entire dataset, including the test set, leading to leakage. For example, using statistics calculated on the entire dataset for normalization rather than just the training set may cause leakage.
- Target variable. Information derived from the target variable might be included in the feature set if the target variable was used to generate features or if data from the future was used to construct the variable.
- Feature engineering. Creating features that directly or indirectly encode information about the target variable results in the model learning from the variable itself, not relevant patterns in the data.
Data Breach vs Data Leakage
In the context of machine learning, data leakage vs data breach refer to distinct data access issues:
Improperly separating train and test datasets, for example, can cause data leakage.
A breach is the unauthorized access, disclosure, or compromise of any sensitive data used in the model. This kind of data exposure might result from a range of vulnerabilities, or unauthorized / incorrect use of 3rd party models by developers.
Data Leakage vs Data Access Exposure
Data access exposure is a holistic approach to security, taking on both data leakage and data loss in machine learning and broader cybersecurity contexts. It identifies vulnerabilities or risks associated with unauthorized access to sensitive or confidential data.
For example, data exposure occurs when weaknesses or loopholes in security measures that protect data allow unauthorized individuals to access information by exposing it to the public internet. Any discussion of data access exposure is really more about proactively preventing exposure of sensitive data by limiting access to that information, and correctly configuring associated application functionality.
It is critical to address data access exposure because it directly impacts the confidentiality, integrity, and availability (CIA) of data. Ensuring proper data exposure and access modeling minimizes risk, maximizes trust, and safeguards assets to keep operations secure and reliable.
Various factors can cause data access exposure, such as inadequate access controls, weak authentication mechanisms, unencrypted data transmission, insecure storage practices, or malicious activities like hacking or insider threats.
Addressing data exposure requires implementing robust access controls, encryption, strong authentication methods, effective logging and threat detection capabilities, regular security audits, and employee training on best practices for data security.
Data Leakage vs Data Loss
Similarly, data leakage and data loss represent distinct data handling issues, but data loss is often related to data breaches and technical failures.
We have discussed why data leakage occurs.
Loss can result in the inability to access or retrieve data. As mentioned, breaches might cause data loss, as can software and hardware issues, human error, natural disasters, and accidental or intentional deletion. Most data loss prevention tools focus on identifying unsafe or non-compliant forms of data transfer.
Data Exfiltration vs Data Leakage
Corruption caused by this kind of data leakage is limited to the internal data model. There is no damage outside the system—unless the flawed model is deployed.
However, data exfiltration poses a significant security risk for companies, especially when it involves sensitive intellectual property (IP) being used to train third-party large language models (LLMs). This can lead to the unauthorized use of the company’s intellectual property, a resulting loss of competitive advantage, and legal/reputational risk.
Similar to a breach, during data exfiltration, an attacker extracts sensitive data from a computer or network without authorization. Their goal is usually financial gain, sabotage, or other malintent.
For SaaS platforms and other third-party systems, as well as subcontractors with access to company data living in cloud systems, the risk of data leakage is exacerbated for several reasons.
Third-party systems and subcontractors expand the attack surface for potential breaches. Each additional entity with access to the data increases the risk of a security incident leading to data leakage.
When data lives across various systems that many parties can access, it presents more monitoring challenges. This complexity makes it easier for malicious actors to exploit vulnerabilities and exfiltrate sensitive information.
Companies may have limited control over how third parties handle their data. Even if they have robust security measures in place within their own infrastructure, weaknesses in third-party systems or subcontractors’ practices can cause data breaches.
Data Leakage Examples
There are several common examples of data leakage:
- Misconfigured SaaS web portals. These make it easier for attackers to access data and harder for users to monitor how data is being stored and used.
- Unauthorized use of 3rd party LLMs. This type of data leakage is really a form of IP theft. More than a security risk, it also presents a potential source of liability for brands.
- Compromised subcontractors. Mishandling of data by 3rd and 4th parties is possible as chains of subcontractors are added to the mix. Complex webs of data leakage make for difficult forensic processes for IT teams.
- Misconfigured storage. Misconfigured cloud storage services may allow public access to sensitive data.
- Unsecured databases. Misconfigured database servers may be left exposed without proper authentication or access controls.
- Exposed Application Programming Interfaces (APIs). Improperly configured without access controls or authentication mechanisms, these may allow unrestricted access and expose sensitive data.
- Open File Transfer Protocol (FTP) servers. Open or configured with weak security settings, FTP servers allow unauthorized users to access and download sensitive files.
- Improper email configuration. Misconfigured email servers or forwarding rules may unintentionally expose sensitive communications or attachments to unintended recipients.
- Unencrypted data transmission. Failure to encrypt data can lead to interception and exposure.
- Time-based data leakage. Failure to properly exclude future data from time-series datasets allows it to leak into the training set. This in turn enables the model to learn from information that would not be available at prediction time.
- Information from test set. Accidentally including test set data during model training, such as unique test set labels or features, produces overly optimistic performance estimates during training.
- Proxy variables. Some proxy variables indirectly leak target variable information and perform poorly. For example, account creation date as a proxy variable for fraud prediction is often limited.
- Cross-validation leakage. Incorrect cross-validation can cause data leakage from the test set into the training process.
These data leakage use cases can occur when the model learns irrelevant patterns that are present merely due to chance. Understanding the various causes and types of data leakage can help focus efforts on detection and prevention.
How to Detect Data Leakage
Detecting causes of data leakage requires careful analysis of the data leakage model and its performance:
- Prevent data exposure. Examine users who have access to identify any that might increase data leakage risk. Limit access to prevent exposure.
- Engage in cross-validation. Use appropriate cross-validation techniques, such as time-series or group-wise cross-validation, to prevent data leakage attacks across folds. Monitor performance across folds to detect significant variations that could suggest data leakage vulnerability.
- Target leakage indicators. Look for signs of target data leakage problems, such as unusually high model performance metrics during training, especially if they cannot be replicated on new, unseen data.
- Holdout validation. Set aside a portion of the data as a validation set and periodically use it to evaluate model performance and to detect any unexpected drops or increases in performance that could indicate data leakage threats.
- Manually inspect data, features, and preprocessing steps. Identify any potential data leakage causes, such as data transformations, feature engineering techniques, or data sources that may inadvertently include information about the target variable.
- Consult experts. Seek input from domain experts or data scientists familiar with data leakage detection and prevention to identify potential sources of leakage and validate the appropriateness of features and preprocessing steps.
- Conduct feature analysis. Examine the features used in the model to identify any that might increase data leakage risk. Identify features that might be too predictive or contain information from the target variable or future data.
These are the basic principles of data leakage detection. There are multiple tools and approaches for implementing them.
How to Prevent Data Leakage
A well-crafted data leakage prevention policy is crucial. Here are some data leakage prevention best practices for the cybersecurity context:
Data leakage monitoring. Continuously monitor with a data leakage solution to detect unexpected behaviors and deviations from expected outcomes.
Conduct regular data audits and maintain documentation. Audits of data sources can identify potential leakage before it happens and ensure data integrity. Documentation facilitates transparency and reproducibility and assists with data leakage risk assessment.
Security and access controls. Implement strong measures to protect sensitive data from unauthorized disclosure. Limit access to datasets, model outputs, and other sensitive information based on role or need as well as data leakage prevention policies.
Employee training and awareness. Comprehensive data leakage protection policy education for employees is critical. Encourage employees to report suspicious activities, security incidents, and potential data leakage incidents promptly to IT or security teams for investigation. Ensure team members understand how any data leakage protection solutions in use work.
What is data leakage prevention?
- Perform cross-validation. Perform cross-validation correctly, with data preparation and separated data folds to prevent leakage between them. Use appropriate data leakage prevention tools and cross-validation techniques, such as k-fold, stratified, or time-series cross-validation, depending on the nature of the data and problem.
- Add noise. Add random noise to input data to smooth the effects of leaking variables.
- Ensure strict data separation. Data leakage prevention tools separate training, validation, and test datasets to prevent information leakage between them.
- Feature engineering. Avoid using features that directly or indirectly encode information about the target variable. Be cautious when creating features from time-related data. Data leakage prevention controls apply feature scaling, imputation, and other preprocessing techniques separately to the training and testing datasets to prevent leakage of information from the test set.
What is Data Leakage Protection?
Data leakage detection techniques and solutions offer a range of capabilities that address various aspects of data leakage protection. In general, they offer several features:
Anomaly detection. Data leakage detection systems monitor data access patterns, user behavior analytics, and behaviors to identify deviations from normal usage which could indicate potential data leakage or unauthorized access.
Data loss prevention (DLP). DLP technologies monitor and filter outbound traffic to identify and block any attempt to transfer sensitive data outside the organizational perimeter.
Regular audits and reviews of system configurations and access controls. This identifies vulnerabilities and ensures compliance with regulatory requirements and industry standards.
Configuration monitoring and management. Data leakage controls continuously monitor and manage system configurations to ensure they adhere to security best practices and alert administrators of deviations and recommended remediation steps.
How Does AppOmni Detect and Prevent Data Leakage?
As the leading SSPM solution, AppOmni detects unintended data exposures and other vulnerabilities or risks caused by customer-side misconfigurations in SaaS platforms. This holistic data access exposure approach to security prevents both data leakage and sensitive data loss in the machine learning niche and in broader cybersecurity contexts.
AppOmni Insights analyzes the various factors that can cause data access exposure, including exposed APIs, improper permissions, incorrect ACLs and IP restrictions, or toxic combinations of misconfigurations, to help users identify issues.
The platform continuously detects these misconfigurations and many similar SaaS access risks, enabling timely, proactive SaaS threat detection, prevention, and guided steps for remediation. AppOmni can alleviate the burden of permission management and offer users full visibility into organizational access.
Learn more about how AppOmni offers continuous data access exposure protection that can help prevent data leakage.